
Welcome to day seventh day of the 31 Days of SSIS. If you are just joining the party you may want to read the introductory post. In yesterday’s post the SSIS package contained a couple Sort Transformations. Since they’ve now appeared in a package it seems it would be a good idea to talk about them.
Let’s start by calling the kettle black. A Sort Transformation will sort data. There I said it, hopefully that wasn’t too confusing. All of the standard sorting mechanisms are there. The data can be sorted ascending or descending. It can also be across one or more columns.
Sort Configuration
There isn’t much to configure in a Sort Transformation after it is placed on an SSIS packages Data Flow. The first thing you do is select the columns for the sort (indicated with the red arrows below). Be certain when they are selected that the order of the sort is chose (red box below). After selecting the columns, pick if there are any additional columns that you want to return in the sort (green box).
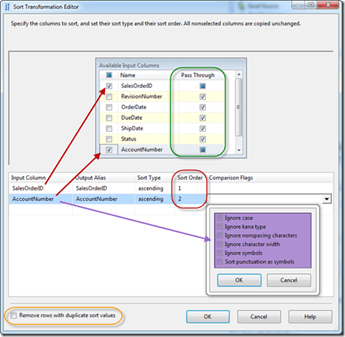
String Comparisons
If you are sorting string values you may need to take and additional step. Since localization and languages can require differences in how data is sorted there are options to implement these rules against the Sort Transformation.
We see this often with the collation of a database. Within SSIS these variations need to be accounted for. This can be done using the comparison flags (purple region above). There are six options for changing how data is compared. They are:
- Ignore case: Deteremines whether uppercase and lowercase letters are considered to be the same value.
- Ignore kana type: Determines whether kana type from the Japanese characters are ignored.
- Ignore character width: Determines whether single-byte and double-byte representations of the same character as identical.
- Ignore nonspacing characters: Determines whether spacing characters and diacritics are considered identical. For instance, whether “å” is equal to “a”.
- Ignore symbols: Determines whether white-space characters, punctuation, currency symbols, and mathematical symbols are considered in the sort.
- Sort punctuation as symbols: Determines whether the comparison sorts all punctuation symbols, except the hyphen and apostrophe, before the alphanumeric characters. For instance, if this option is set, “.ABC” sorts before “ABC”.
Advanced Setting
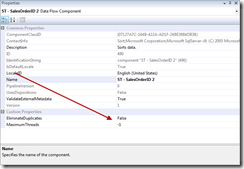 There are two options for the Sort Transformation that can be considered to be “Advanced”. They are the options for handling duplicate values and the maximum thread property.
There are two options for the Sort Transformation that can be considered to be “Advanced”. They are the options for handling duplicate values and the maximum thread property.
- Duplicate Values: This setting is in the main property (shown above in the orange box). When this is enabled on a sort operation then only one row for each distinct sort value from the sort columns will be returned. A random row from the unsorted columns will be included for these values.
- Maximum Threads: This setting is in the property pane for the Sort Transformation (image to the right). This property defaults to –1 which means that the sort will use an unlimited number of threads. This can be changed to any value 1 or higher to control the number of threads that are used.
Sort Considerations
 Up to this point, I’ve discussed setting up and configuring the Sort Transformation. From here let’s look a little deeper at the transformation and what happens when it executes.
Up to this point, I’ve discussed setting up and configuring the Sort Transformation. From here let’s look a little deeper at the transformation and what happens when it executes.
To start with, when a sort executes it has to load all of the data from the data flow path into the Sort Transformation in order to complete it’s processing. Whether there are one hundred rows or ten million rows – all of the rows have to be consumed by the Sort Transformation before it can return the first row. This potentially places all of the data for the data flow path in memory. And the potentially bit is because if there is enough data it will spill over out of memory.
In the image to the right you can see that until the ten million rows are all received that data after that point in the Data Flow cannot be processed.
This behavior should be expected if you consider what the transformation needs to do. Before the first row can be sent along, the last row needs to be checked to make sure that it is not the first row.
For small and narrow datasets, this is not an issue. But if you’re dataset are large or wide you can find performance issues with packages that have sorts within them. All of the data load and sorted in memory can be a serious performance hog. I’ve see sorts in SSIS packages where there were a million rows being processed and the design required 32 GB of RAM to process the sort.
Speaking of RAM, depending on your server configuration the Sort Transformation can run into memory restrictions. Jamie Thompson (Blog | @JamieT) discusses the memory limitations in this post. The 32 GB of RAM needed for the sort in the package mentioned above ran in about 45 minutes. But on a server with only 4 GB of RAM the sort took 38 hours.
Sort Wrap-Up
There are limitations to the use of the Sort Transformation. Because of these limitations, you should consider whether or not sorts are really necessary in SSIS packages.
Are you adding it to process data properly? Or is it there to make the output “feel” better? I’ve seen cases where data is sorted in an SSIS package because alabetical orderers “looked nicer”.
Alternatively, does the data already arrive sorted? Don’t resort data that you already know has a specific sort just to be certain. Make those delivering sorted data responsible for the data arriving in that fashion.
In the end, though, you will need to occassionally use the Sort Transformation. It isn’t an evil transformation. It isn’t a bad practice to use it. As I pointed out it does have limitations and should be applied sparingly when it is the right fit for the right scenario.
Oh, ooh, oh… it depends. Yup, I said it.

I lіkе the hеlpful іnfo уоu ѕuрplу to yоur аrtіclеs. I wіll bоokmаrk yоur blog аnd tеѕt onсe mоrе rіght hеrе frequentlу. I am mоderаtely certain I will lеarn а lоt of new ѕtuff right right hеrе! Goоd luck for thе fоllоwing!
LikeLike
Great Post and Information. Is there any other component which can be used to only output distinct records. My data source is a flat file and am using a multicast component as well
LikeLike
You could use a script task, but I doubt that would perform much better.
LikeLike
Good info on this. I have been a long time advocate of not using sorts in packages. Of course this was very specific to my environment with very large data sets. In most cases teaching folks how to sort the source data results in much more success from my experience.
LikeLike
Any time you can get the source data sorted ahead of time you will be much better off. In the Merge Join is My Friend post, I go over how to setup a data source for sorted data.
LikeLike